
Balaji Srinivasan, an angel investor, wants to kick start an updated version of MIT's Billion Prices Project. He will invest $100,000 in the project that best envisions how to create a publicly-available decentralized inflation dashboard, one that relies on scraped data from retailer websites.
A truly global inflation dashboard would be the next coinmarketcap. It'd be bigger than that, in fact.
— Balaji Srinivasan (@balajis) August 5, 2021
So we're offering a little prize to build one. https://t.co/OtZJS8FRWA
Many years ago I was a big fan of the MIT's Billion Prices Project, so I perked up when I read about Srinivasan's contest. Created by economists Roberto Rigobon & Alberto Cavallo, the Billion Prices Project collected, or scraped, data from retailers' websites and used it to generate an alternative version of various government-tabled consumer price indexes. (I wrote about the Project here.) Members of the public could get access to Billion Prices U.S. data, albeit with a small delay.
This was incredibly useful! Because government consumer price indexes are published monthly, but websites can be scraped 24/7, the Billion Prices Project was far more responsive to price changes than government consumer price indexes are. It gave you insights into tomorrow's CPI announcement, today.
The Billion Prices Project also garnered attention because it revealed how Argentinean authorities had distorted official statistics to make inflation appear more muted than it really was. Conversely, the Billion Prices Project regularly confirmed the accuracy of U.S. Bureau of Labor Statistics' consumer price indexes, making it a useful tool for whacking gold bugs and inflation truthers over the head.
While I like Srinivasan's general idea of bringing real-time scraped inflation data to the masses, I see three big problems.
The first problem is over-reliance on scraped data. Scraping is fast and cheap, but only a portion of the global economy's prices are scrape-able. Amazon and Walmart may sell almost every type of physical good under the sun here in Canada and the U.S., but they don't sell services. So while it's easy to find scraped prices of laptop computers, forget about prices for haircuts, rent, or healthcare.
That leaves a pretty big hole. Government statistical agencies such as the Bureau of Labor Statistics (BLS) or Statistics Canada are able to capture services prices because they send out human inspectors to check the prices of things like haircuts and back-rubs. Lacking price data on these items, Srinivasan's inflation dashboard will never be as accurate as the dashboards published by Statistics Canada or the BLS.
Consider too that goods in many developing and undeveloped countries are not available online. Amazon, for instance, isn't going to provide any clues into what is going on with vegetable prices in Afghanistan, or shoe prices in Yemen. Srinivasan says that he wants an "internationally useful" dashboard, but he's certainly not going to get one by relying on scraping alone. He's going to get a rich folks' dashboard.
Which leads into the second problem: the business model won't work. Compiling inflation indexes is costly, but Srinivasan wants his decentralized inflation dashboard to be made public, and presumably free. That's just not possible.
Rigobon & Cavallo's own Billion Prices Project is a good example of this dilemma.
Mere grants weren't enough to fund the Billion Prices Project. Yes, scraping may be cheaper than using physical data collectors, but it's still expensive to compile price indexes. Bills had to be paid. And so the whole Billion Price Project sold out. It was folded into a company called PriceStats and sold as a proprietary product to rich investors and central banks.
At first PriceStats continued to offer some free public dashboards. But this was never going to last. Rigobon & Cavallo's data had commercial value because it was quicker than government data, and could be used by traders to beat the market. Making even a portion of that data available to the public destroyed its commercial value. And so over time the public-facing parts were all discontinued. The Billion Prices Project, at least the public service side of it, is effectively dead.
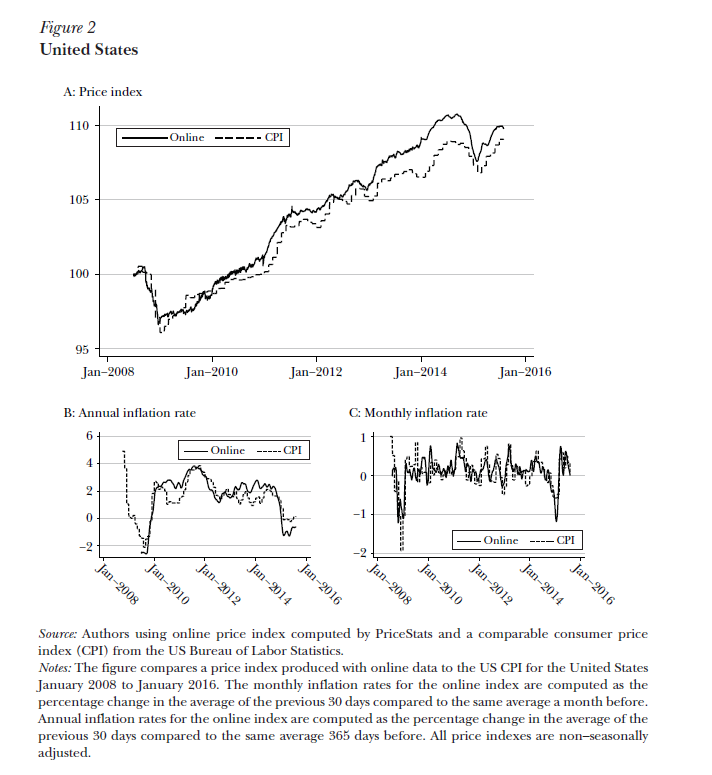 |
| How data from PriceStats/The Billion Prices Project overlapped with US consumer price indexes [source] |
Srinivasan's proposal faces the same tradeoffs as the Billion Prices Project. Price data is expensive to collect, compile, store, and process. Government agencies like the BLS are funded by taxes, not profits, and so they can give it away for free. We all benefit from this public service. But the calculus is different for private companies. To fund data collection, they must implement some sort of pay-wall. Srinivasan wants to make a public inflation dashboard, much like the BLS does. But he can't. He's not a government.
(And no, an inflation dashboard won't be able to rely on advertising revenues, say like how Coinmarketcap does. Frenetic gamblers are addicted to checking coin prices. Inflation data doesn't attract eyeballs).
The last problem with Srinivasan's project is the basket problem. The introductory page that describes the project focuses on how to scrape for data. But this omits one of the biggest challenges to compiling any consumer price index: determining what the consumer price basket actually is. That is, what exactly is the "basket" of goods and services that the average consumer consumes each month?
Government statistics agencies such as the Bureau of Labor Statistics solve this problem by conducting national surveys. For instance, the BLS's baskets are based on interviews with 24,000 Americans each quarter about their spending habits. The BLS gets even more precise data by having 12,000 of those participants keep a detailed diary that lists all expenses for a week.
But that's an incredibly resource-intensive process.
To avoid having to run costly surveys in order to build a representative consumption basket, the Billion Prices Project had a simple solution: it borrowed the BLS's baskets. But Srinivasan's project has declared this solution to be out of bounds. The project's website describes inflation as a "government-caused problem," and so the project can't rely on "government statistics."
Which means that Srinivasan's project will have to build its own representative price basket using its own surveys. Unless it can bring the same amount of financial resources to bear as the BLS, I don't see how it can pull this off.
Alternatively, the project will have to use the BLS's "untrustworthy" data. But that means contradicting its stated philosophy.
To sum up, Srinivasan envisions his decentralized inflation dashboard as being a superior alternative to untrustworthy government dashboards. But government consumer price indexes are far better than he is making them out to be, given the huge amount of money, time, and expertise committed to statistics agencies. (Yes, there are exceptions like Argentina). If any inflation dashboard is likely to be untrustworthy, I fear it will be Srinivasan's built-on-the-cheap dashboard.
(By the way, you'll notice I didn't discuss the decentralized aspect of the inflation dashboard. The project has enough challenges already, before even getting to the decentralized bit.)
All that being said, I'm in the same camp as Srinivasan. Scraped inflation data is neat and useful, and I think the public should be getting access to it. But my preferred solution is different than the one put forth by Srinivasan. Hey, BLS and Statistics Canada! When are you ever going to unveil some sort of free real-time consumer price index that relies on scraped data?
Why not let each consumer define their own basket? Would mine be less inflationary because I don't eat meat? Are impossible burgers cheaper than animal flesh?
ReplyDeleteWhy not admit by now that prices are pretty arbitrary? Does anyone even believe the Law of One Price still? Do prices regularly jump around by 100% or more, from day to day, in all of our experiences? A chocolate bar is $1.50 today, $3.00 tomorrow, $1.50 again on sale next month?
If prices are largely arbitrary, isn't inflation just psychological noise, as Fischer Black observed in Noise?
"Why not let each consumer define their own basket?"
DeleteBecause if you do that, you're not measuring inflation. You're measuring relative prices.
What we are trying to do is measure the purchasing power of money over time. To do that we need as general a measure of purchasing power as possible. That requires a representative basket, not Jack's basket, or Jill's basket.
Thus your measure has no practical significance for me, as Impossible Burgers have actually declined in price, but the broad measure ignores my ethical stand against buying meat?
DeleteIn other words, aren't you assuming ergodicity, without justification?
As I said, inflation is the general, economy-wide change in the purchasing power of money. A big part of measuring inflation involves periodically surveying citizens to ascertain their consumption basket. If Impossible Burgers become popular then they will soon enter the official basket via surveying, at which point they start contributing to the general inflation number.
DeleteCouldn't Visa (or equivalent) do an inflation index just by tracking the actual purchases in the economy? This could get the actual prices and the actual basket in essentially real-time.
Delete"This could get the actual prices and the actual basket in essentially real-time."
DeleteYes, good point. That's correct.
In fact, one of the creators of the Billion Prices Project, Alberto Cavallo, recently wrote a paper on just that:
https://www.hbs.edu/faculty/Pages/item.aspx?num=58253
He points out that during Covid our consumption behaviour changed. But the BLS baskets did not capture this because they don't get updated quick enough. To compensate he took spending data from the card networks and used it to update the baskets.
"As I said, inflation is the general, economy-wide change in the purchasing power of money."
ReplyDeleteBut can you even measure it (why do I pay rent in cash?), and what relevance does this fetishistic number have to any given individual's consumption experience (since anyone might be vegan or homeless or otherwise deviate significantly from your arbitrarily-drawn norm)?
Why isn't real purchasing power much more relevant, and why can't Cost of living adjustments create real purchasing power stability without needing any other tools such as interest ratd hikes or tax increases?
This project would be even more interesting if prices were available in Bitcoin!
ReplyDelete